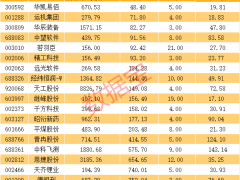
在人工智能算力競爭愈發激烈的當下,英偉達憑借GPU在市場中占據主導地位,然而如今其地位正受到挑戰。近期,蘋果披露其Apple Intelligence全部由TPU訓練;Anthropic簽下數十億美元訂單采購TPU訓練Claude;meta也與谷歌簽署數十億美元協議租用TPU運行Llama。這一系列動態表明,谷歌的TPU正逐漸在市場中嶄露頭角。
TPU作為谷歌的“秘密武器”,在過去十年驅動著谷歌幾乎所有核心產品。直到TPU訓練的Gemini 3取得出色成果,人們才開始重新審視這款從搜索推薦系統中誕生的定制芯片。前谷歌TPU工程師Henry深度參與了三代TPU的研發,見證了大模型時代TPU的關鍵轉型。他從硬件架構、軟件生態、生產供應鏈博弈三個維度,揭開了TPU的神秘面紗。
TPU與GPU在設計哲學上截然不同。Henry用“流水線”與“大廚們”來比喻兩者架構差異:GPU起源于圖形處理,采用SIMT架構,如同廚房里眾多獨立思考的大廚并行處理多種任務;而TPU是專為機器學習矩陣計算定制的加速器,通過芯片間互聯構建3D Torus網絡,讓數千張芯片協同工作,如同一張芯片,減少了調度和調控,提高了計算單元使用率。
在大規模部署場景中,TPU展現出獨特優勢。Henry表示,在軟硬件深度協同下,TPU能對整顆TPU Pod進行全局算子融合與內存管理優化,將硬件性能“榨干”到極致,實現比GPU更低的推理成本。例如,谷歌的Ironwood芯片在物理參數上接近英偉達的GB200,在訓練Gemini模型時,若谷歌為其他大模型公司定制,性價比(TCO)可能更高。因為TPU可根據已知任務負載進行物理芯片和軟件層面的定制,保證每個計算單元都有任務,提高利用率。
然而,TPU也存在明顯短板。在軟件生態方面,盡管TPU已向外部客戶開放,但其編譯工具XLA仍是一個“黑盒”,外部團隊難以獨立完成調優。開發者使用TPU時,上層可選用PyTorch、JAX和TensorFlow等語言,XLA將其轉化為TPU指令,但外部開發者很難獨立處理或修補bug,需依賴谷歌工程師或其專門對接外部客戶的軟件組。
產能方面,TPU面臨諸多挑戰。HBM(高帶寬內存)生產被SK hynix、三星和Micron三家公司壟斷,英偉達是HBM最大客戶,TPU作為次要客戶,此前難以獲得優質訂單。同時,CoWoS是臺積電的核心產能,TPU的HBM內存芯片和計算芯片需通過2.5D stacking封裝成集成芯片,此過程谷歌和博通都無法完成,只能依賴臺積電。良率也是問題,TPU主打芯片間通信,失敗率高于GPU,且作為定制芯片,良率不佳則芯片報廢,而GPU可降級使用。
在定制芯片領域,TPU需提前預測模型走向。以MoE(混合專家模型)為例,此前在TPU和GPU上運行效果不佳,直到TPU V4推出3D torus架構和OCS(光交換機),通過軟件更改通信路徑,解決了MoE的痛點。但芯片設計流程漫長,從設計到量產最快需兩年到兩年半、三年,而模型每6個月就變化一次,TPU需在兩年前預測模型方向。雖然目前V7押對了方向,但未來若模型范式變化,TPU的先發優勢可能被蠶食。
供應鏈方面,博通在TPU生產中扮演關鍵角色。博通負責TPU的通信ICI設計,將芯片物理連接并布局拓撲網絡。谷歌與博通的合作可爭取到更好的CoWoS和HBM產能,但博通議價權逐漸增大,對谷歌成本控制不利。同時,HBM產能被英偉達壟斷,未來幾年HBM可能決定芯片訓練效率上限。
回顧TPU的發展歷程,其最初是針對內部CNN大模型的加速器,第一代僅為推理芯片。Jeff Dean和圖靈獎獲得者David Patterson深度參與了第一代架構設計。第二代成為旗艦訓練模型,用于AlphaGo、PaLM等訓練。此后,針對推薦和排序算法加入Sparse Core,V5、V6進入大模型時代,針對Transformer進行優化并推出推理版本。
英偉達收購的Groq公司也值得關注。Groq踩準了推理、ASIC和Agent元年三個時間點,其芯片主做推理,針對低延遲場景,是編譯器的公司而非芯片公司。創始人Jonathan Ross曾是TPU編譯器團隊成員,將TPU編譯器經驗帶到Groq。Groq的LPU通過編譯器精準確定每個計算單元任務,確定性高,適合Agent、實時語音和高頻交易等對延遲要求高的場景。
隨著人工智能發展,推理芯片市場將分層并分應用場景。谷歌和TPU將占據大規模部署的高層市場,中間和下層市場將有更多參與者。未來,TPU和GPU將并存,形成定制與通用、垂類場景相結合的健康生態,為用戶帶來成本降低后的無限可能。