在全球人工智能技術競爭日益激烈的背景下,智算中心(AIDC)正成為支撐人工智能大模型訓練與推理的核心基礎設施。這場以算力、網絡架構和數據中心重構為核心的變革,正在推動整個行業向更高性能、更低時延的方向邁進,其目標直指突破傳統數據中心的性能邊界,構建適應人工智能時代的新型基礎設施體系。
生成式人工智能的爆發式發展,正在引發全球算力需求的指數級增長。據市場預測,全球生成式人工智能市場規模預計將在2028年突破5000億美元大關。與此同時,中國和全球的智能算力規模正在快速擴張,預計到2030年,智能算力將占據整體算力市場的90%以上份額。這一趨勢背后,是大模型參數規模從千億級向萬億級甚至十萬億級的跨越式發展,直接推動支撐其訓練的GPU集群規模從千卡級別迅速擴展至萬卡、十萬卡級別。這種規模擴張不僅意味著更多芯片的堆疊,更對連接這些芯片的數據中心網絡提出了前所未有的技術要求,包括超高帶寬、超低時延和零丟包的無損傳輸能力。網絡端口速率正在從400Gbps向800Gbps甚至1.6Tbps快速演進,帶動交換機市場迎來爆發式增長。
構建如此龐大的智能計算集群,網絡技術成為最大的瓶頸之一。在萬卡級集群中,GPU之間的梯度同步要求微秒級的時延控制,單次訓練產生的網絡流量高達數十EB級別。任何微小的丟包或延遲都可能導致訓練效率急劇下降甚至訓練失敗。與此同時,單個機柜能耗高達50kW的智能計算中心,其網絡設備功耗占比可達20%-30%,能耗優化和成本控制成為亟待解決的關鍵問題。傳統基于CPU的TCP/IP協議棧和"盡力而為"的網絡架構已經無法滿足這些嚴苛要求,技術體系的全面重構成為必然選擇。
為應對這些挑戰,行業正在從硬件到協議層面進行全方位創新。在物理層,全光互聯技術成為關鍵突破口。高速光模塊(400G/800G/1.6T)、光電合封(CPO)技術以及用于遠距離互聯的相干可插拔光模塊(如800G ZR)正在顯著提升帶寬、降低時延和功耗。空芯光纖等前沿技術更將傳輸時延進一步降低了三分之一。在網絡架構方面,傳統CLOS胖樹架構正在向Dragonfly、3D Torus等新型拓撲結構演進,這些新架構能夠有效縮短網絡直徑,減少通信跳數。光電混合架構(如引入光電路交換機OCS)則實現了帶寬的靈活調度和拓撲快速重構,在提升性能的同時降低成本和能耗。
在協議與控制層面,基于RDMA(遠程直接內存訪問)的技術(如InfiniBand和RoCEv2)通過內存零拷貝和內核旁路機制,成為實現低時延無損傳輸的基礎。為更精細地管理海量數據流,擁塞控制技術正在從被動的PFC、ECN機制向基于信用授權的主動預防式以及AI賦能的智能調控演進。通過帶內遙測(INT)實時感知網絡狀態,并利用AI進行流量預測、擁塞預警和算法參數調優,網絡正在變得"自適應"和"自優化"。負載均衡技術也從粗放的逐流調度向逐包、甚至逐信元的精細化調度發展。這些技術進步共同構成了智能計算網絡的技術革新體系。
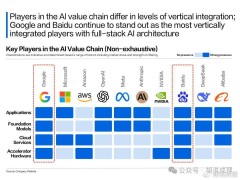
在這場智能計算基礎設施競賽中,不同市場參與者展現出差異化的發展路徑。電信運營商憑借其覆蓋全國的骨干網絡優勢,主打"云網融合"戰略,強調算力與網絡的深度協同。通過"算力即服務"等形式,為企業提供低時延、高可靠的算力連接和整體解決方案。而互聯網巨頭則依托自身強大的研發實力和業務需求,傾向于自研硬件(如AI芯片、交換機)和軟件,構建軟硬一體的超大規模智能計算集群。這種路徑的優勢在于能夠實現技術的快速迭代和極致的性能優化,既能支撐自身海量AI應用,又能對外輸出算力服務。
隨著技術不斷演進,智能計算網絡的發展正在超越單純追求規模和帶寬的階段,邁向更高層次的智能化與協同化。AI原生技術正在深入融入網絡設計、運維和優化的全流程,實現網絡的自我感知、決策和修復能力。"算網一體"概念正在從理論走向實踐,實現算力與網絡資源的全局智能調度。同時,"東數西算"等國家戰略催生的跨地域算力協同需求,正在推動廣域無損網絡技術走向成熟,使得分布在不同地理位置的智能計算中心能夠像一臺計算機一樣高效協同工作。這場以網絡重構為核心的智能計算革命,不僅將決定人工智能技術突破的天花板,更將重塑全球數字經濟的競爭格局。