在虛擬世界中,讓數字人物實現如同真人般的實時互動,一直是技術領域的一大難題。阿里巴巴通義實驗室的研究團隊近日宣布,他們成功開發出一種名為“結點強制”的AI視頻生成技術,這項技術能夠讓虛擬人物在直播、視頻通話等場景中,展現出流暢自然的表情和動作,為虛擬互動帶來全新體驗。
傳統視頻生成技術往往面臨兩難選擇:要么追求高質量而犧牲速度,要么保證實時性卻難以維持畫面穩定。例如,擴散變換器模型能生成逼真畫面,但計算耗時過長;因果自回歸模型響應迅速,卻容易出現畫面閃爍、身份漂移等問題。研究團隊針對這些痛點,提出了創新的解決方案。
“結點強制”技術的核心在于三大創新機制。首先是分段生成與全局錨定策略,系統將長視頻分割為固定長度的片段進行處理,同時緩存參考圖像的關鍵特征作為“身份錨點”,確保人物形象始終如一。這種設計既控制了計算負擔,又避免了長期生成中的身份丟失。
第二個創新是時間紐帶模塊,通過創建重疊生成區域實現片段間的平滑過渡。系統在生成當前片段時,會同步生成下一片段的前幾幀,并將前一片段的末尾幀作為后續生成的條件輸入。這種接力式的設計,有效解決了傳統模型在片段邊界處的不連續問題。
第三個創新是全局上下文前瞻運行策略,系統動態調整參考圖像的時間位置,使其始終位于當前生成幀的“未來”,為整個過程提供穩定的語義導向。這種前瞻機制如同為登山者指引山頂方向,防止了誤差累積和身份漂移。
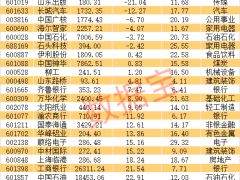
實驗數據顯示,該技術在多個關鍵指標上表現優異。在300個肖像動畫測試中,時間閃爍指標達到98.50分,顯著優于其他方法。系統能夠穩定生成超過3分鐘的連續動畫,且視覺質量保持穩定。與MIDAS和TalkingMachines等競爭技術相比,“結點強制”在視覺穩定性、時間連貫性和身份保持等方面均展現出明顯優勢。
這項技術的應用前景廣泛。在虛擬直播領域,內容創作者可以打造24小時不間斷的高質量虛擬主播;在線教育領域,虛擬教師能夠根據學生反饋實時調整教學風格;客戶服務行業可開發高度擬人化的虛擬客服代表;娛樂產業則能實現數字化表演和經典角色的復現。這些應用不僅提升了用戶體驗,還為相關行業帶來了新的發展機遇。
技術實現方面,研究團隊基于Wan2.1-T2V1.3B模型進行開發,采用漸進式優化策略。系統推理速度達到17.5 FPS,滿足實時應用需求。高效的KV緩存機制和優化的注意力計算,使得系統在保持高質量輸出的同時,將延遲控制在可接受范圍內。
盡管“結點強制”技術取得了顯著進展,但其發展也帶來了一些需要關注的問題。深度偽造技術的潛在風險不容忽視,惡意使用可能對個人隱私和社會信任造成沖擊。虛擬演員技術的完善可能對傳統表演行業產生影響,需要幫助從業者適應技術變革,尋找新的職業發展路徑。
研究團隊表示,未來將繼續探索因果學習模型與雙向教師模型之間的理論差距,并將這一框架擴展到更廣泛的可控生成任務中。隨著硬件計算能力的提升和算法優化的深入,這類技術有望在更多設備上普及應用,從高端服務器到消費級顯卡,再到移動設備,實時高質量視頻生成可能成為各種設備的標準功能。