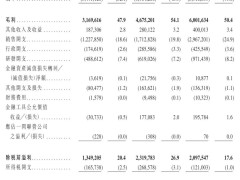
隨著人工智能大模型參數規模持續膨脹,全球算力基礎設施正經歷一場以互聯架構升級為核心的變革。據行業分析,2026年將成為關鍵轉折點,商用GPU出貨量與云服務商自研ASIC芯片部署規模同步攀升,推動數據中心內部通信方式發生根本性轉變。這場變革中,光通信與銅纜技術形成互補格局,共同支撐起超大規模算力集群的運轉需求。
英偉達最新發布的Rubin架構為行業樹立了技術標桿。其NVL 144機柜通過第六代NVLink與NVSwitch技術,實現單柜129.6TB/s的雙向帶寬。在物理連接層面,該架構采用1.6T規格的AEC銅纜完成GPU與交換芯片的高密度互聯,單通道速率提升至224G。這種設計使銅纜在機柜內部短距傳輸中占據主導地位,同時通過胖樹拓撲結構解決超大規模集群的網絡擁塞問題。測算顯示,構建9216張GPU集群需要288臺脊交換機,光模塊與芯片配比達到1:12,直接拉動高端光模塊市場需求。
谷歌TPU集群的互聯方案展現出獨特的定制化特征。其64卡機柜采用3D Torus拓撲結構,通過混合連接方式實現4.8TB/s的雙向互聯速率。柜內網絡中,80根銅纜承擔非相鄰板卡間的直接通信任務,而光模塊則負責機柜外部連接。在超大規模集群部署中,谷歌引入光路交換技術(OCS),通過64臺300x300端口設備動態調整光路連接,使十萬卡級別訓練任務的功耗降低30%以上,同時提升網絡配置靈活性。
亞馬遜Trainium3芯片的組網方案突出物理層創新。NVL72*2配置中,144顆芯片通過PCB印制電路板、背板連接器及AEC銅纜實現三層級聯,單機柜內部部署216根64端口PCIe銅纜。這種全銅互聯方案在保證400G低延遲帶寬的同時,使機柜功耗降低25%。在集群擴展方面,亞馬遜采用雙平面網絡架構,ENA網絡處理前端流量,EFA網絡專注算力通信,通過Clos拓撲結構支持線性擴展至13萬張芯片規模。
meta的解耦架構(DSF)為行業提供新思路。Minerva機柜采用Tomahawk5交換芯片與112G PAM4銅纜背板組合,實現204.8Tbps對稱帶寬。在超大規模集群部署中,DSF兩級交換網絡通過1:1帶寬收斂比確保無阻塞傳輸,構建18432顆芯片集群需要消耗18.4萬個800G光模塊。這種設計凸顯光模塊在長距互聯中的不可替代性,同時證明銅纜技術在短距場景仍具成本優勢。
行業分析指出,2026年AI算力建設將呈現"光銅共進"特征。在機柜內部,DAC、AEC等高速銅纜憑借低功耗、低成本優勢成為主流選擇,帶動相關產業鏈產能擴張。而在節點間通信領域,隨著集群規模突破十萬卡門檻,光模塊需求將呈指數級增長。特別是英偉達、meta等企業的高配方案中,光芯片與光模塊配比顯著提升,可能引發新一輪產能競爭。建議關注光通信芯片與高速銅纜連接器領域的頭部企業,這些公司在技術迭代與產能布局方面已占據先發優勢。